





引子
“一个进程绑定一个端口号”,这是显而易见的原则
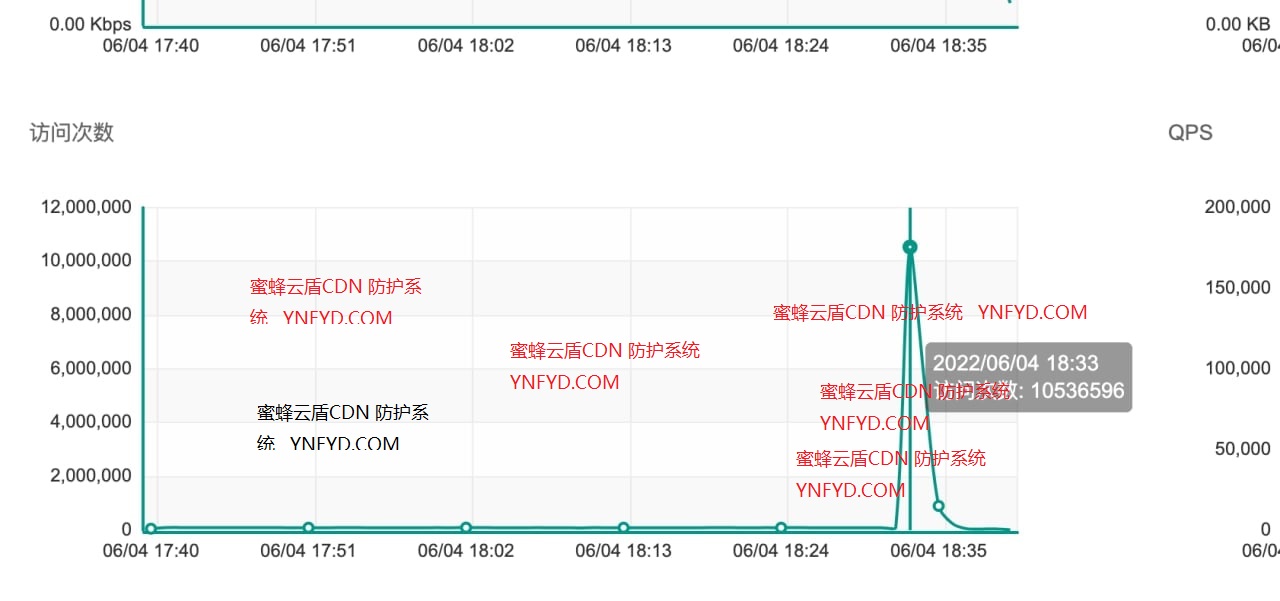
当客户端要向服务器建立TCP连接时,会随机选择一个空闲端口,我们现在假设所有TCP都是长连接,那么当空闲端口被占用完后,自然无法创建更多的TCP连接,此时会报Cannot assign requested address的错误。我们都知道,端口号的取值范围是0~65535,既然端口号这么有限,服务器又是如何承受百万级甚至更高的并发量的?队列?缓存?多路复用?其实都没说到点子上
想象一下,一个nginx服务只占用一个80端口,难道它同时只能支撑一条TCP连接吗,显然不是的。那它又是如何区分到达同一端口的不同请求的呢?
TCP四元组
TCP四元组,简单来说,就是
<源IP地址,目标IP地址,源端口号,目标端口号>
在linux源码中,使用结构体sock_common表示
include/net/sock.h
struct sock_common {
/* skc_daddr and skc_rcv_saddr must be grouped on a 8 bytes aligned
* address on 64bit arches : cf INET_MATCH()
*/
union {
__addrpair skc_addrpair;
struct {
__be32 skc_daddr; // 外部/目的IPV4地址
__be32 skc_rcv_saddr; // 本地绑定IPV4地址
};
};
// ...
/* skc_dport && skc_num must be grouped as well */
union {
__portpair skc_portpair; //
struct {
__be16 skc_dport; // inet_dport占位符
__u16 skc_num; // inet_num占位符
};
};
// ...
}
真实的sock_common比上面展示的要复杂的多,但要理解四元组,看这些部分就足够了
网络连接
在连接建立之初,服务器会根据四元组信息为每条不同的TCP连接建立socket,并保存在内存中。当客户端向服务端发送数据包时,会将四元组信息携带在ip头信息当中,服务端收到数据包之后,解析四元组信息,在内存中查找对应的socket。服务器使用不同的socket和不同的客户端进行通信,也就是说,只要四元组中有任意元素不相同,服务器就能判断出这是一个不同的连接,会使用不同的socket与其通信,而socket和端口并不是一一绑定的关系,只要资源充足,一个服务器进程可以创建出几百万条socket连接。

客户端端口复用
我们现在知道,服务器可以复用同一端口创建多条TCP连接,那另一方面,是否意味着客户端一条连接就需要占用一个端口呢?
对于客户端来说,源IP地址一定是确定的,那么如果要请求特定目标IP的特定端口,为了保证四元组中至少有一个元素不同,那么确实需要绑定多个端口才能并发创建多个连接。但这并不意味着一个客户端端口只能承载一个连接,只要目标IP和目标端口任意一个发生变化,就可以在同一端口下继续创建多条连接。
理论承载量
假设有一台服务器,上面运行着Nginx服务,占用了80端口,那么它理论上的最大并发承载量是多少呢,根据四元组规则, 他的理论承载能力为:
2^32 * 2^16
其中2^32表示IPV4理论个数,2^16表示端口最大数量
当然没有哪台服务器可以承受几百万亿的并发量,究其原因,是因为每创建一个socket连接,都需要占用一定的内存。而且对于linux来说,创建连接实际上就是打开一个新文件,而为了防止打开过多文件导致系统崩溃,linux在系统层面和用户层面均设置了最大文件打开数。


留言0